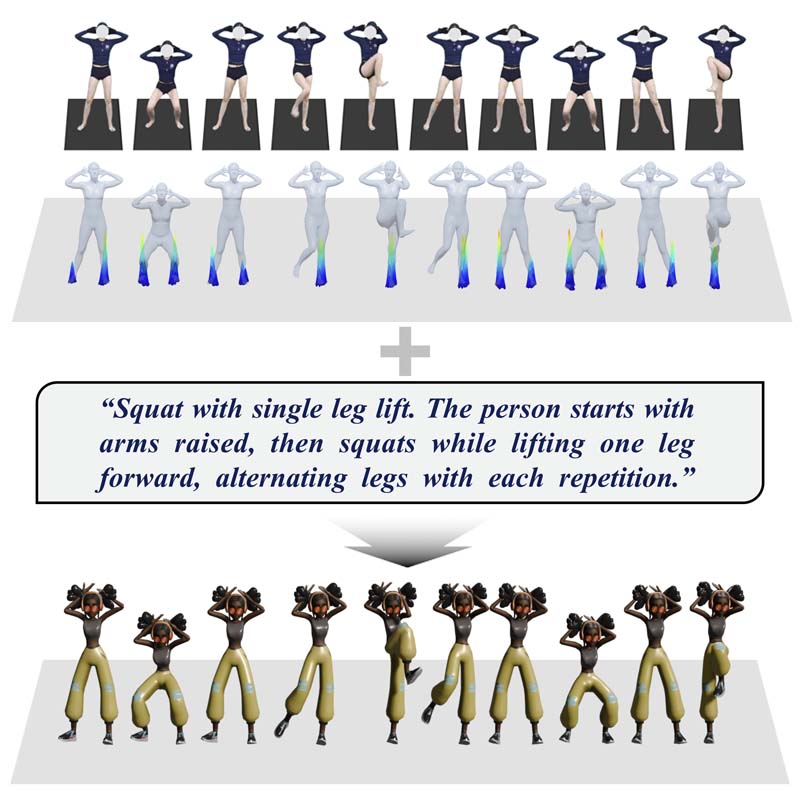
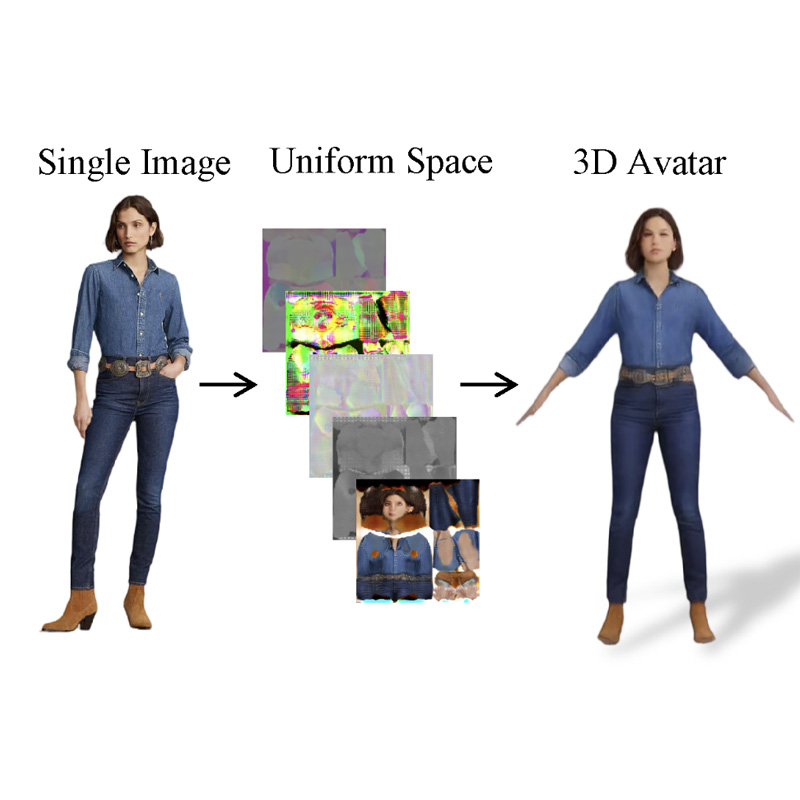
CrowdGaussian addresses the challenges of multi-person 3D reconstruction from a single image by utilizing a self-supervised adaptation pipeline and Self-Calibrated Learning to generate photorealistic and geometrically complete 3D Gaussian Splatting representations despite heavy occlusions and low clarity.
CVPR 2026